
CAP Theorem: Explained
⚠️ This post is outdated. I’ve significantly revised my thinking on this topic. Please read the updated version: CAP Theorem Revisited instead. I’m keeping this post live to avoid breaking links, but the content below contains outdated information.
Several years ago, building performance into a software system was simple - you either increased your hardware resources (scale up) or modified your application to run more efficiently (performance tuning). Today, there's a third option: horizontal scaling (scale out).
Horizontal scaling of software systems has become necessary in recent years, due to the global nature of computing and the ever-increasing performance demands on applications. In many cases, it is no longer acceptable to run a single server with a single database in a single data center adjacent to your company's headquarters. We need truly distributed environments to tackle the business challenges of today.
Unfortunately, the performance benefits that horizontal scaling provides come at a cost - complexity. Distributed systems introduce many more factors into the performance equation than existed before. Data records vary across clients/nodes in different locations. Single points of failure destroy system up-time, and intermittent network issues creep up at the worst possible time.
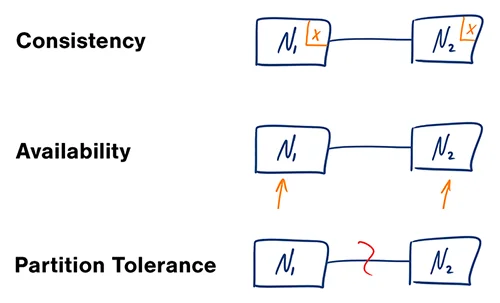
These concerns of consistency (C), availability (A), and partition tolerance (P) across distributed systems make up what Eric Brewer coined as the CAP Theorem. Simply put, the CAP theorem demonstrates that any distributed system cannot guaranty C, A, and P simultaneously, rather, trade-offs must be made at a point-in-time to achieve the level of performance and availability required for a specific task.
[C] Consistency - All nodes see the same data at the same time.
Simply put, performing a read operation will return the value of the most recent write operation causing all nodes to return the same data. A system has consistency if a transaction starts with the system in a consistent state, and ends with the system in a consistent state. In this model, a system can (and does) shift into an inconsistent state during a transaction, but the entire transaction gets rolled back if there is an error during any stage in the process.
Typical relational databases are consistent: SQL Server, MySQL, and PostgreSQL.
[A] Availability - Every request gets a response on success/failure.
Achieving availability in a distributed system requires that the system remains operational 100% of the time. Every client gets a response, regardless of the state of any individual node in the system. This metric is trivial to measure: either you can submit read/write commands, or you cannot.
Typical relational databases are also available: SQL Server, MySQL, and PostgreSQL. This means that relational databases exist in the CA space - consistency and availability. However, CA is not only reserved for relational databases - some document-oriented tools like ElasticSearch also fall under the CA umbrella.
[P] Partition Tolerance - System continues to work despite message loss or partial failure.
Most people think of their data store as a single node in the network. "This is our production SQL Server instance". Anyone who has run a production instance for more than four minutes, quickly realizes that this creates a single point of failure. A system that is partition-tolerant can sustain any amount of network failure that doesn't result in a failure of the entire network. Data records are sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages.
Storage systems that fall under Partition Tolerance with Consistency (CP): MongoDB, Redis, AppFabric Caching, and MemcacheDB. CP systems make for excellent distributed caches since every client gets the same data, and the system is partitioned across network boundaries.
Storage systems that fall under Partition Tolerance with Availability (AP) include DynamoDB, CouchDB, and Cassandra.

Conclusion
Distributed systems allow us to achieve a level of computing power and availability that were simply not available in yesteryears. Our systems have higher performance, lower latency, and near 100% up-time in data centers that span the entire globe. Best of all, the systems of today are run on commodity hardware that is easily obtainable and configurable with costs approaching $0.
All of this computing power and benefit comes at a price, however. Distributed systems are more complex than their single-network counterparts. There are many more tools and skills that need to be acquired in order to create a truly scalable, high performance system. Understanding the complexity incurred in distributed systems, making the appropriate trade-offs for the task at hand (CAP), and selecting the right tool for the job are all critical skills in a world where computing systems are moving out, not up.
What did you think of this essay?