
CAP Theorem: Revisited
👋 Still relevant since 2014: I’m glad you’re one of the thousands who find this post helpful. If you enjoy this article, I’d love for you to stick around and check out some of my more recent writing on technology, leadership, strategy, and AI. Explore recent posts →
Note: Close to two months ago, I wrote a blog post explaining the CAP Theorem. Since publishing, I've come to realize that my thinking on the subject was quite outdated and is no longer applicable to the real world. I've attempted to make up for that in this post.
In today's technical landscape, we are witnessing a strong and increasing desire to scale systems out when additional resources (compute, storage, etc.) are needed to successfully complete workloads in a reasonable time frame. This is accomplished through adding additional commodity hardware to a system to handle the increased load. As a result of this scaling strategy, an additional penalty of complexity is incurred in the system. This is where the CAP theorem comes into play.
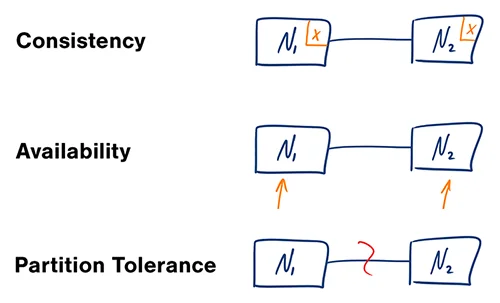
The CAP Theorem states that, in a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed. However, as you will see below, you don't have as many options here as you might think.
- Consistency - A read is guaranteed to return the most recent write for a given client.
- Availability - A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
- Partition Tolerance - The system will continue to function when network partitions occur.
Before moving further, we need to set one thing straight. Object Oriented Programming != Network Programming! There are assumptions that we take for granted when building applications that share memory, which break down as soon as nodes are split across space and time.
One such fallacy of distributed computing is that networks are reliable. They aren't. Networks and parts of networks go down frequently and unexpectedly. Network failures happen to your system and you don't get to choose when they occur.
Given that networks aren't completely reliable, you must tolerate partitions in a distributed system, period. Fortunately, though, you get to choose what to do when a partition does occur. According to the CAP theorem, this means we are left with two options: Consistency and Availability.
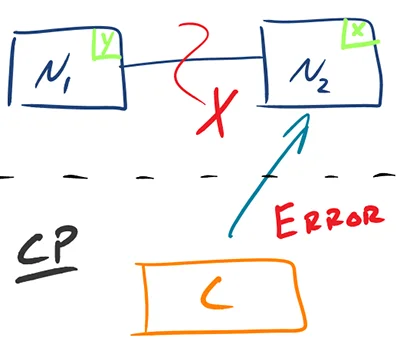
- CP - Consistency/Partition Tolerance - Wait for a response from the partitioned node which could result in a timeout error. The system can also choose to return an error, depending on the scenario you desire. Choose Consistency over Availability when your business requirements dictate atomic reads and writes.
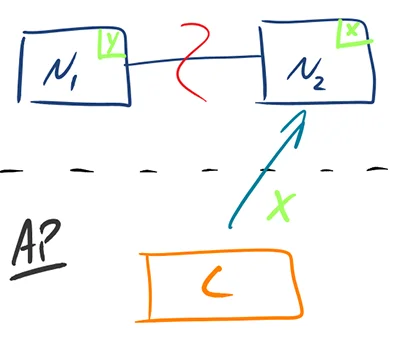
- AP - Availability/Partition Tolerance - Return the most recent version of the data you have, which could be stale. This system state will also accept writes that can be processed later when the partition is resolved. Choose Availability over Consistency when your business requirements allow for some flexibility around when the data in the system synchronizes. Availability is also a compelling option when the system needs to continue to function in spite of external errors (shopping carts, etc.)
The decision between Consistency and Availability is a software trade off. You can choose what to do in the face of a network partition - the control is in your hands. Network outages, both temporary and permanent, are a fact of life and occur whether you want them to or not - this exists outside of your software.
Building distributed systems provide many advantages, but also adds complexity. Understanding the trade-offs available to you in the face of network errors, and choosing the right path is vital to the success of your application. Failing to get this right from the beginning could doom your application to failure before your first deployment.
What did you think of this essay?